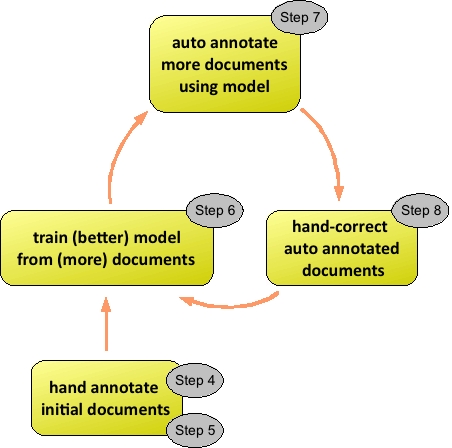
We also present a more detailed
illustration of the lifecycle of document sets, again annotated
with those steps which are relevant:
Now that we've talked about some of the MAT basics, we can see
how to put them together to achieve one of MAT's main
capabilities, which is to assist you in incrementally building a gold standard corpus (i.e., a
body of annotated documents which are believed to be completely
and correctly annotated according to your set of desired
annotations), and a trained
model (a data object for your automated annotation engine
which has been constructed using your corpus, such that it can be
used to annotate additional documents, with reasonable accuracy),
using the tag-a-little, learn-a-little (TALLAL) loop strategy.
If you've read the tutorials, and the sections under "What you need to know about..." that cover annotations, tasks and training, choosing a mode, and workspaces, you've already seen all the steps in TALLAL. In this document, we're going to make absolutely sure that you understand how all these steps fit together.
First, a reminder: you may recall from the discussion of annotations that MAT 2.0 does
not provide automated training and tagging for complex
annotations. We'll be addressing this in a future release, but in
MAT 2.0, the full TALLAL loop is only available for simple span
annotations.
With that caveat, here's how to use the various pieces of MAT to
accomplish this larger goal, in ten main steps that we'll review
in a minute. We've annotated the TALLAL loop illustration from the
introduction with those steps which
are relevant:
We also present a more detailed
illustration of the lifecycle of document sets, again annotated
with those steps which are relevant:
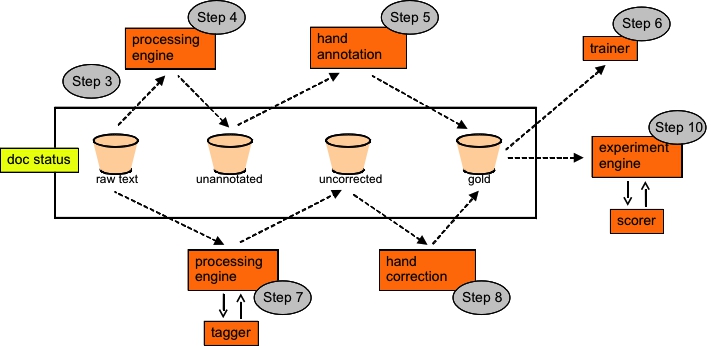
In the table below, we summarize ten steps involved in TALLAL, as illustrated in these two diagrams and in the documentation you've already read. The TALLAL loop is available in either file mode or workspace mode; we're going to present these two "tracks" alongside each other, showing how they differ and overlap.
| File mode |
Workspace mode |
|
|---|---|---|
|
Step 1: configure and install your task |
This step should already have been done for you, especially if you've received this toolkit as a tarball. If not, ask your task maintainer. | |
| Step 2: choose an interaction mode |
This section
tells you how to choose between file mode and workspace
mode. Other relevant documentation pages are: |
|
| Step 3: organize your files |
If you chose file mode, you should set aside directories for storing the annotated documents, and develop some heuristic for keeping track of which documents you've finished. | If you chose workspace mode, you should
create your workspace and import some documents. If you want
to import more documents later, you can do that. The following documentation sections are relevant:
|
| Step 4:
prepare documents for hand annotation |
In order to "seed" the TALLAL loop, you'll need to hand-annotate some documents, and in order to do that, you'll need to ensure that the documents are ready to be annotated. | |
|
You can prepare these documents using the steps in your
workflow that precede the hand annotation step. For hand
annotation, it's probably easiest to do it in the UI,
since you'll need to load the documents into the UI
anyway. You'll need to select the appropriate workflow,
which will likely be named "Hand annotation". MAT's
default tagging and training engine, Carafe,
requires that documents be tokenized, so you should make
sure that this step is included in the workflow you use. Tutorial 1 will get you
started. The following documentation sections are also relevant: |
Preparing documents for annotation should be taken care of for you when you import documents into the workspace. |
|
| Step 5: hand
annotate the document |
Tutorial 1
covers loading a file in file mode via "File -> Open
file...". |
Tutorial 6
covers opening a workspace and a file within a workspace. |
|
Once the document has been loaded into the UI, hand annotation is the same in both modes. Tutorial 1 covers this step, and the documentation on using the UI describes hand annotation in more detail (among other things). You don't have to complete the hand annotation in one swoop; you can always open the document again and do more annotation. Be sure to save the document when you're done. |
||
| To save, you should press the "File" item in the menu bar, and select "Save..." and then "mat-json". | You can simply save the document, or mark the
document as gold, which saves the document and indicates
that you're satisfied that the annotations in the document
are correct and complete. |
|
| Step 6: build
a model |
Once you've annotated some documents, you can build a model from those documents. You'll be able to use this model to automatically tag more documents, which will reduce the time it takes to complete the annotation. | |
| Tutorial 2 covers this. For more detail, see the documentation on the MATModelBuilder tool. If your task is configured appropriately, you'll have the option of saving the model as the default model for the task. | Tutorial 6 covers this; you'll use the MATWorkspaceEngine on the command line to perform the "modelbuild" operation. For this operation, you have to option of performing the next step at the same time. | |
| Step 7:
automatically tag some documents |
Next, you'll want to automatically tag your next batch of documents. | |
|
Tutorial 5 covers using the
command line MATEngine to
process a file or a directory of files; tutorial 3 covers using UI to
process one file at a time. On the command line, you'll
have to know which steps in which workflow you need to
perform to automatically tag; this depends on the
configuration of your task. In the UI, you'll have to know
which workflow to choose. Other documentation that may be relevant: |
Tutorial 6
covers this; you'll use the MATWorkspaceEngine on
the command line to perform the "modelbuild" operation. If
there are no unannotated or uncorrected files, you'll need
to import some more files into your workspace. Other documentation that may be relevant: |
|
| Step 8: hand correct the documents |
This step is identical to step 5 above. | |
| Step 9: lather, rinse, repeat |
At this point, you
have two paths to creating correct, complete documents:
either completely by hand, through steps 4 and 5, or
semi-automatically, through steps 7 and 8. You also know how
to build a model, which you can do at any time based on your
correct, complete documents. |
|
| Step 10: check your progress |
At any point after you have some correct, complete documents, you can find out how you're doing. (This process ought to be built into the model building stage in workspace mode, but it isn't yet.) Tutorial 7 covers the use of the MATExperimentEngine for this purpose. You'll configure an XML file which describes which documents you want to use as your test and training corpora, how many alternative models you want to build, and which runs you want to perform, and you'll get back detailed, Excel- or OpenOffice-compatible spreadsheets describing the performance of your automated annotation tool. | |